微处理器体系机构以及功能模块简介 链接到标题
基本功能 链接到标题
- 指令控制:顺序
- 操作控制:可能调整顺序
- 时间控制:wake&sleep
- 数据加工:就是数据运算
- 中断处理:这是重点,之后有一个章节会专门讲
主要性能指标 链接到标题
- 主频
- 外频
- 倍频=主频×外频
- 地址总线宽度
- 数据总线宽度
基本结构 链接到标题
从结构上可以分成下面四种
- 运算器(ALU)
- 寄存器组
- 控制器
- 内总线 进一步的分类将在下面介绍。
数据通路 链接到标题
运算器(ALU)、寄存器组、内总线这三部分称为数据通路。
控制器 链接到标题
时序控制部件 链接到标题
指令译码部件 链接到标题
- 微程序(CISC)
- 硬联逻辑(RISC)
更细致的对比见下表
硬联逻辑处理器 微程序处理器 需求背景 需求量大,但性能要求不高 需要高性能,而存储器访问速度太慢 目标 减少制造成本 设计新CPU时能减少重复设计费用 方法 减少使用的门电路总数 把指令集与硬件的设计分开 用途 支持RISC 支持CISC
指令系统 链接到标题
指令要素 链接到标题
- 操作码
- 源操作数(这就牵涉到数据的储存位置)
- 结果/目标操作数
- 下一条指令
分类 链接到标题
数据传输 链接到标题
- 数据传送范围:
- 寄存器
- 存储器
- I/O接口
- 数据传送宽度:一般为固定值(如8、16、32bit)
数据运算 链接到标题
即加减乘除和逻辑运算。 该类指令需要明确操作数的类型和长度
控制类 链接到标题
用于改变正常的程序执行流程,完成程序的跳转,主要包括转移指令和过程指令。 ·
指令格式 链接到标题
操作码字段 链接到标题
- 说明CPU应进行的操作,
- 按操作类型分组:同类操作要求同样或类似的控制信号,因此编码也类似(有尽可能多的公共位)
操作数字段/地址字段 链接到标题
- 说明源操作数和目的操作数存放的位置信息(R、M或I/O);
- 说明源操作数和目的操作数的数据类型;
下一条指令地址字段 链接到标题
- 如紧跟当前指令,在主存或虚存中,则不需显示引用;(连续储存)
- 如可能产生跳转,则需要显示给出指令存储地址(类似于指针)
寻址方式 链接到标题
链表式 链接到标题
(我自己起的名字)
- 立即数寻址:在指令码中指定操作数! alt text
- 寄存器寻址:给出存储在寄存器中的操作数的地址

- 存储器直接寻址给出存储在存储器中的操作数的地址
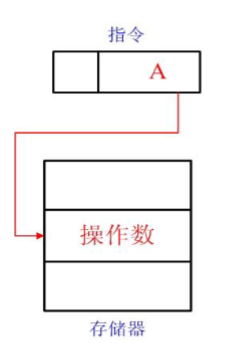
- 存储器间接寻址:操作数存储在存储器中,其在寄存器组中有一个地址,而指令中的地址字段给出的是寄存器组中操作数在存储器中的地址(有点晕,看图很清晰)

{kind=link}
链接到标题
位移式 链接到标题
- 位移量寻址
- 变址寻址
- 比例尺寻址
- PC相对寻址
流水线技术 链接到标题
概念 链接到标题
延迟 链接到标题
- 从头到尾执行一条指令所需要的时间(ps=$10^{-12}$s)
- 以最慢的部件的延迟为准!(详见ppt上170*3=510ps的例子)
吞吐量 链接到标题
- 单位时间内完成的指令数 $$ (1s/170ps) $$ 通过拆分组合逻辑,加入了寄存器,延迟会增大,但是可以增大吞吐量(见课件p38)。
流水线的局限性 链接到标题
流水线各段的延迟 链接到标题
也就是说产生了硬件空闲,从而使得性能下降
流水线段数过多 链接到标题
也就是中间插入的寄存器多了,延迟也就增加了,产生两个后果
- 寄存器贵,并且也会增加硬件控制复杂
- 性能没有成比例增加,即效率变低了。
流水线指令相关的局限性 链接到标题
即出现了冒险。
数据冒险 链接到标题
- 违背写后读规则(RAW)
- 违背写后写规则(WAW)
- 违背读后写规则(WAR) 一句话,就是冲突冒险,即当前指令的源操作数与前一条指令的目标操作数相同。 不过有一些解决方法
- 在相关指令之间增加等待周期:(当然,这不是最优解)
- 定向技术:将结果数据从其产生的地方直接传送到所有需要它的功能部件
- 乱序执行:用流水线调度(scheduling)技术来重新组织指令顺序 (见课件p44的例子)
结构冒险 链接到标题
同一时间争同一资源
控制冒险 链接到标题
无法立即给出转移地址(可以理解为一种延迟)
指令流水线的性能指标 链接到标题
吞吐量 链接到标题
m级流水线每一条指令都要经过m个阶段(ai给的结论,未在权威资料中验证,单貌似是对的),有了这个结论才能很好的理解下面的公式
- 吞吐量$T_p$:单位时间内完成的指令数
- 最大吞吐量$T_{pmax}$:流水线达到稳定状态后的吞吐量(即在大量代码满负荷情况下的理想流水线状态)。
若一个m级线性流水线各级时长(即拍长)均为$\Delta t$,则连续处理n条指令时的实际吞吐量$T_p$为 $$ T_p=\frac{n}{m\Delta t+(n-1)\Delta t}=\frac{1}{\left[1+\frac{m-1}{n}\right]\Delta t} $$ 其中$m\Delta t$可以理解为建立流水线的过程,$(n-1)\Delta t$就是完成剩下的指令所用的时间。 当$n\to \infty$,就可以得到 $$ T_{pmax}=\frac{1}{\Delta t} $$ s
加速比 链接到标题
定义:非流水线执行时间与流水线执行时间之比。。
反应的是流水线对不使用流水线的优化程度。
若一个m级线性流水线各级时长(即拍长)均为$\Delta t$,则连续处 理n条指令时的加速比$S_p$为: $$ S_p=\frac{T_{\text{串行}}}{T_{\text{流水}}}=\frac{nm\Delta t}{m\Delta t+(n-1)\Delta t}=\frac{m}{\frac{m-1}{n}} $$ 同样取极限($n\to\infty,S_p\to m$)可以知道理想流水线的加速比与流水线的段数m相同。
效率 链接到标题
即各段硬件的利用率
定义:若一个m级线性流水线各级时长(即拍长)均为$\Delta t$,则连续处理n条指令时的效率E定义为指令完成需要用的硬件资源(时空区)与指令完成实际用到的硬件资源(时空区)的比值 $$ E_p=\frac{nm\Delta t}{[m^2+(n-1)m]\Delta t}=\frac{1}{1+\frac{m-1}{n}} $$ 当$n\to\infty$,$E\to 1$,即流过流水线的指令越多,流水线效率越高。
我是这样子理解这个公式的分母的,类似于整块被占用区域染指的时空即使有空位也已是被占用的空间,效率小于1也正是由此而来。
典型微处理体系结构 链接到标题
ARM体系结构 链接到标题
结构 链接到标题
- RISC指令集,内核小, 功耗低、成本低
- 哈佛结构
- 运算器操作数只能从 寄存器输入/输出
- 采用桶式移位器处理 ALU输入,灵活高速
系统结构特点 链接到标题
- RISC指令规则,适合流水设计
- 寻址方式灵活简单,执行效率高,仅Load和Store指令可以 访问存储器
- 所有指令的条件执行实现最快速的代码执行
- 支持Thumb(16 位)/ARM(32 位)双指令集,能很好的兼 容8 位/16 位器件 53
Intel 8086体系结构 链接到标题
结构 链接到标题
- 冯式结构
- 运算器操作数可以从寄存器、存储器或I/O端口获得
- 分成两大功能部件EU、BIU 54
特点 链接到标题
- 为保持兼容性采用变长的、高度不规则的 CISC指令集。
- 是基于专用寄存器组的二地址存储器-寄存 器(M-R)机:对于二元操作,一个操作数总 是指定在寄存器中,另一个操作数可以从 存储器或寄存器中读取